
Meta 今(19)日宣布新一代 Llama 3 初始的兩個模型已可廣泛使用。此版本包含預訓練和指令微調的語言模型,其中的 8B(80 億)和 70B(700 億)參數,可支援更多元的使用情境。新一代 Llama 在多項產業指標上展現了卓越的成效,並提供許多新的功能,包括更精準的推理能力,是目前同業中最佳的開源模型。此外,延續 Meta 長期以來的開放創新模式,Llama 3 將釋出供社群運用。Meta 將全面引領新的 AI 技術創新浪潮,從應用程式、開發人員工具、評估,再到優化推理能力等,並鼓勵開發者開始建立專屬的內容,給予更多回饋與建議。
Llama 3 的目標
Meta 希望透過建立與目前專有模型並駕齊驅的最佳開放模型 Llama 3 ,回應開發人員的回饋,並提高 Llama 3 的整體實用性,同時持續領導負責任地使用並部署大型語言模型。Meta 秉持及早釋出與頻繁更新的開源精神,讓社群搶先試驗這些仍在開發階段的模型。今日所推出的以文字為基礎的模型為 Llama 3 系列的第一波模型。Meta 期待讓 Llama 3 在近日具備多語言和多模態、有更長的上下文語境,並繼續提升推理和編寫程式碼等核心大型語言模型能力的整體表現。
Llama 3 卓越的效能
Llama 3 中全新 8B 和 70B 參數的模型,相較於 Llama 2 有大幅的進步,並為此規模的大型語言模型立下新標準。得益於預訓練與後訓練技術的進展,Meta 的預訓練和指令微調模型是目前 8B 及 70B 參數規模的最佳模型。Meta 在後訓練程序流程的改進大幅降低錯誤拒絕率(False Rejection Rate, FRR),改善一致性,並提升模型反應的多樣性。同時,在推理、程式碼生成和指令遵循等功能亦有顯著提升,讓 Llama 3 更易於操控。
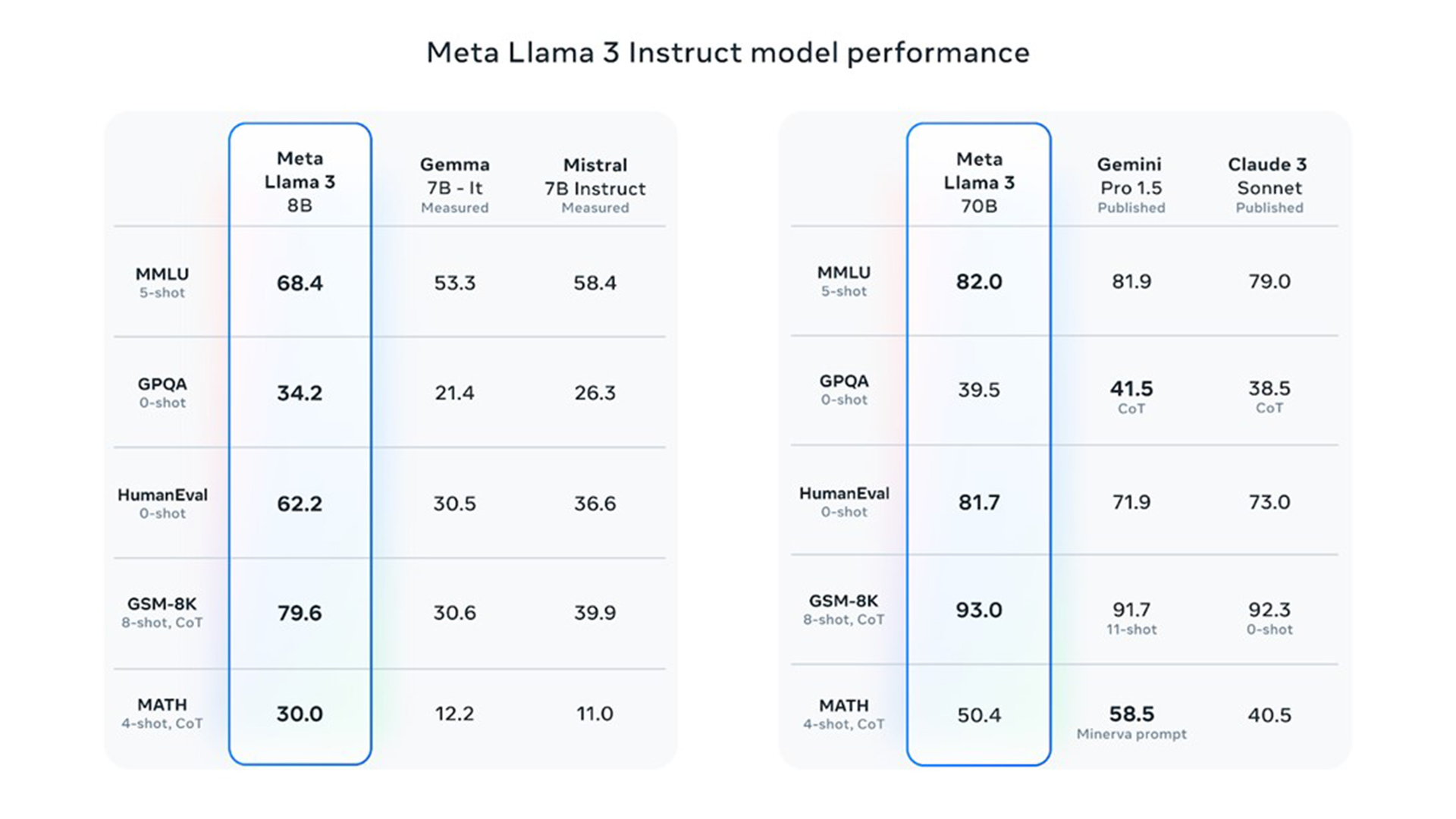
在 Llama 3 的開發過程中,Meta 不僅研究模型在基準測試中的表現,並嘗試為真實的情境優化效能。為此,Meta 全新開發優質的人類評估集(human evaluation set),包含 1,800 個提示,涵蓋 12 個關鍵使用情境,例如尋求建議、腦力激盪、分類、封閉式問答、編寫程式碼、創意寫作、擷取訊息、扮演角色 / 人物、開放式問答、推理、改寫與總結。為了防止模型在此評估集上不小心過度擬合(Overfitting),Meta 更限制內部模型建立團隊對模型的存取。
系統性地負責任開發
Meta 設計的 Llama 3 確保採用領先業界的方法,採用全新的架構以系統性的方式負責任地部署模型。在不同的開發者依其終極目標而設計的系統中,Meta 的 Llama 系統中的基礎模型,由開發者駕馭整體系統,全面地掌握並消弭風險。
在確保模型安全性上,指令微調也同等重要,因此 Meta 進行內部與外部的紅隊測試(red-teamed tested),以確保其安全性。Meta 的紅隊測試方式運用人類專家及自動化方式,產生對抗性提示,試圖引導出有問題的回應。例如,大家對化學、生物、網路安全等風險領域相關的誤用風險,進行全面的測試。這些測試都將不斷迭代更新,並用於為即將發布的模型進行安全微調,提供資訊。更多詳情請參考 Meta 的模型卡。
隨著生成式 AI 領域迅速的發展,Meta 相信開放的方式,是整合生態系並減輕潛在危害的重要途徑之一。身為生態系的一員,Meta 正在更新其負責任使用指南(Responsible Use Guide, RUG),提供負責任地開發大型語言模型的全面性指南。如同 RUG 中所概述,Meta 建議根據應用程式的內容指南,檢示並過濾所有輸入與輸出內容。此外,Meta 亦鼓勵開發人員考慮使用許多雲端服務供應商提供內容檢核的 API,以及其他用於負責任部署的工具。
立即試用 Meta Llama 3
前往 Llama 3 網站下載模型並參考新手指南,以取得所有可用平台的清單。



